最近一年多都没有写博客了,技术上做了很多有意义的事情,也有一些经验上的积累,逐步沉淀到博客上。
今天回答某公司的技术上的一些疑问,把问题和回答贴上来。逐步养自己的技术观。
jdk提供了比较多的线程间同步工具,比如Lock,CountDownLatch,Condition来完成线程间的同步,但是这些高级工具在某些场景可能显得太重量级了,本文简单探讨下不同的实现方式的。
我们假设如下场景,线程A创建任务id=1发起远程调用,响应时,io线程解码id,并通知线程A继续执行。定义如下接口:
public interface FutureResult {
Object get(long timeout, @NotNull TimeUnit unit) throws TimeoutException;
void set(Object Result);
boolean isDone();
Integer getId();
Map<Integer, FutureResult> FUTURE_RESULTs = Maps.newConcurrentHashMap();
static void set(Integer id, Object response) {
final FutureResult future = FUTURE_RESULTs.remove(id);
if (future != null) {
future.set(response);
}
}
AtomicInteger idx = new AtomicInteger();
static Integer getNextId() {
return idx.incrementAndGet();
}
}
@Slf4j
public class LockSupportFutureResult implements FutureResult {
private Integer id;
private volatile Object result;
private Thread runner;
public LockSupportFutureResult() {
id = FutureResult.getNextId();
FUTURE_RESULTs.put(id, this);
}
public Object get(long timeout, @NotNull TimeUnit unit) throws TimeoutException {
if (result != null) {
return result;
}
long nanos = unit.toNanos(timeout);
final long deadline = System.nanoTime() + nanos;
runner = Thread.currentThread();
try {
for (; ; ) {
LockSupport.parkNanos(this, nanos);
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
throw new TimeoutException();
} else {
if (result != null) {
return result;
}
}
}
} finally {
FUTURE_RESULTs.remove(this.id);
}
}
public void set(Object response) {
LockSupport.unpark(this.runner);
this.result = response;
}
public boolean isDone() {
return this.result != null;
}
public Integer getId() {
return id;
}
}
@Slf4j
public class FutureTaskResult extends FutureTask implements FutureResult {
private static Callable DO_NOTHING = () -> null;
private Integer id;
public FutureTaskResult() {
super(DO_NOTHING);
id = FutureResult.getNextId();
FUTURE_RESULTs.put(id, this);
}
public Integer getId() {
return id;
}
public void set(Object o) {
super.set(o);
}
@Override
public Object get(long timeout, @NotNull TimeUnit unit) throws TimeoutException {
try {
return super.get(timeout, unit);
} catch (InterruptedException | ExecutionException e) {
throw new RuntimeException(e);
} finally {
FUTURE_RESULTs.remove(this.id);
}
}
}
使用CountDownLatch,ReentrantLock,内部使用AbstractQueuedSynchronizer数据结构来处理多个等待者,当请求数量很大时,这种开销也不容小视。如果非常关注性能可以考虑直接用LockSupport,担心hold不住的话可以考虑用FutureTask.
服务发现用于动态感知服务提供方地址,并提供服务路由分发策略能力。
客户端从注册中心获取服务列表,客户端监听服务列表的变化,客户端通过路由策略选择合适的服务端地址。
服务端在停服务时,需要先通知客户端不要发送新请求过来,等服务端把当前请求处理完后,才断开连接。
代理端对外提供服务,主要用于对外请求路由。代理端(比如nginx/haproxy)转发请求到后端服务。后端服务暴露地址到注册中心,代理程序动态获取服务地址。
nginx可以试试nginx-upsync-module
在k8s内部,采用nginx+dns+k8s proxy实现。
http://coolshell.cn/articles/17459.html
前段时间写了一段公司的公关文(CUI NIU BI),强迫自己写了5个9。
作者讲了几个大实话:
如果你没有一套科学的牛逼的软件工程的管理,没有牛逼先进的自动化的运维工具,没有技术能力很牛逼的工程师团队,怎么可能出现高可用的系统啊。
深层次的东西则是——对工程这门科学的尊重:1.对待技术的态度 2.一个公司的工程文化 3.领导者对工程的尊重
佛渡有缘人,点到即止,不强求。
也许把SLA写到合同里,我就不敢乱吹牛逼了。
https://www.infoq.com/articles/spring-cloud-service-wiring
这篇文章聊到了spring cloud如何提供配置管理、服务发现、服务路由能力。结合我们的现状谈谈:
Enabling Dynamic Refresh做法优雅多不少ABOUT False Sharing:
Most high performance processors, insert a cache buffer between slow memory and the high speed registers of the CPU. Accessing a memory location causes a slice of actual memory (a cache line) containing the memory location requested to be copied into the cache. Subsequent references to the same memory location or those around it can probably be satisfied out of the cache until the system determines it is necessary to maintain the coherency between cache and memory.
Each update of an individual element of a cache line marks the line as invalid. Other processors accessing a different element in the same line see the line marked as invalid. They are forced to fetch a more recent copy of the line from memory or elsewhere, even though the element accessed has not been modified. This is because cache coherency is maintained on a cache-line basis, and not for individual elements. As a result there will be an increase in interconnect traffic and overhead.
当下列条件满足时,False sharing极大降低了并发性能。
java8 引入了@Contended,在对象编译时,编译器会插入padding,防止多个数据在一个cache line中。
https://github.com/m0wfo/false-sharing-demo测试结果:
[0] % java -XX:-RestrictContended -jar target/false-sharing-demo-1.0.0-SNAPSHOT.jar plain
Updating unpadded version 1B times Took: 55.457223514sec
Updating @Contended version 1B times Took: 7.387646696sec
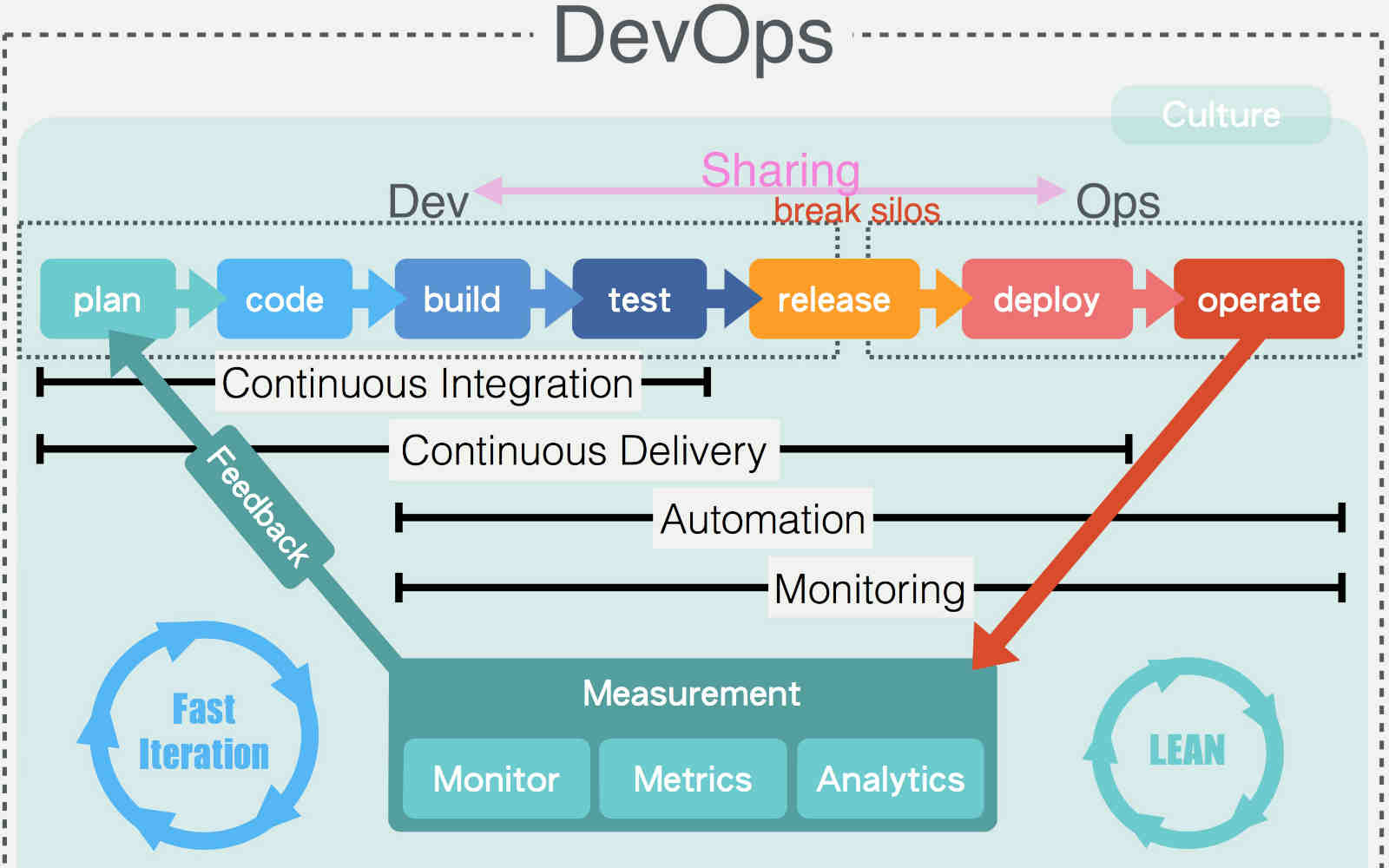
最近在做DEVOPS,看技术的出发点有所变化,正好看到这篇文章,总结下自己。
架构其实是发现利益相关者(stakeholder),然后解决他们的关注点(concerns)
业务方,产品经理,客户/用户,开发经理,工程师,项目经理,测试人员,运维人员,产品运营人员等等都有可能是利益相关者,架构师要充分和利益相关者沟通,深入理解他们的关注点和痛点,并出架构解决这些关注点。
架构师在这里也定位为一个好的需求分析师,但是架构师往往会从自己的角度(利益相关或者立场相关)来设计。我之前一直做开发工作,在技术选型或者研究时,对于可运维性考虑得比较少,在痛过几次后,发现监控的价值,来补充相关metrics的能力。
Architecture represents the significant design decisions that shape a system, where significant is measured by cost of change.
架构的目标是用于管理复杂性、易变性和不确定性,以确保在长期的系统演化过程中,一部分架构的变化不会对架构的其它部分产生不必要的负面影响。
这里补充一点,需要考虑easy to find the problem。除了合理的规划日志,我们要做到failfast。当关键资源依赖条件不满足,我们最好是把问题用最显示的方式暴露出来,而不是让它在那里一直报错。
做技术架构的都有点完美主义倾向,一开始往往喜欢求大求全,忽视架构的演化和迭代性,这种倾向易造产品和用户之间不能形成有效快速的反馈,产品不满足最终用户需求.
在系统真正地投入生产使用之前,再好的架构都只是假设,产品越晚被使用者使用,失败的成本和风险就越高,而小步行进,通过MVP快速实验,获取客户反馈,迭代演化产品,能有效地减少失败的成本和风险。
好的架构是衍变出来的,而非设计出来的。
第一条道路,系统思维,开发驱动的组织机体,其能力不是制作软件,而是持续的交付客户价值,架构师需要有全局视角和系统思维(System Thinking),深入理解整个价值交付链,从业务需求、研发、测试、集成,到部署运维,这条价值链的效率并不依赖于单个或者几个环节,局部优化的结果往往是全局受损,架构师要站在系统高度去优化整个价值交付链,让企业和客户之间形成快速和高效的价值传递。
第二条道路,强化反馈环,任何过程改进的目标都是加强和缩短反馈环。
收集->测量->调整->闭环重复,在有测量数据和反馈的基础上,系统、应用、流程和客户体验才有可能获得持续的提升和改善,否则没有数据的所谓改进只能靠拍脑袋或者说猜测。
这里提到监控的重要性,没有测量,就没有改进和提升,MDD这偏文章有点意思,通过分层和可用的性能指标让开发人员了解项目业务方面的内容,反过来,业务人员也能理解项目技术方面的内容,看到开发人员所面临的问题和我们的负载局限。
第三条道路,鼓励勇于承担责任,冒险试错和持续提升的文化。
最后,贴上一张关于DevOps的图。
http://www.infoq.com/cn/articles/database-timestamp-01
http://www.infoq.com/cn/articles/database-timestamp-01
http://www.infoq.com/cn/articles/database-timestamp-01
此文讲明白了时序数据库,最近也在纠结这个事(原来一直看好opentsdb,但是没有深入调研opentsdb的细节,对es也不是太了解),这里总结下全文。
时间序列数据库除了提供查询能力外,我们也希望能够提供在查询阶段做聚合能力。
聚合有有三个步骤:
ES在这三个步骤上都做得很好。
如何快速检索?

lucene倒排索引由Term index->Term Dictionary->Posting List构成。TI是对TD做的索引,实现对Term的快速查找。Mysql使用b-tree排序存储TD在磁盘上;Lucene增加了TI保存在内存中,查询效率更高。
如何联合索引查询?
对于age=18 AND gender=女的查询过滤。mysql的做法是(如果两个列都建立了索引,当然gender列做索引在mysql上没有什么卵用)先在索引上找age=18的所有id,然后遍历id匹配。
Elasticsearch支持:
使用skip list数据结构。同时遍历gender和age的posting list,互相skip;
利用skip list(Level0存储原始有序数据,level1存储部分数据,查找时从level1跳过部分数据),跳过了遍历的成本,并且用Frame of Reference(计算差值,分块后,每个块内部选择合适的bit来存储)压缩存储。
使用bitset数据结构,对gender和age两个filter分别求出bitset,对两个bitset做AN操作。
大多数场景下,bitset非常稀疏,bitset压缩空间很大。lucene采用Roaring Bitmap,算法也有点意思:
计算N/65536和N%65536的值,把N/65536相同的分为一个组,分组后根据每个组的情况用short数字或者bitset。
如何减少文档数?
一般采用数据库会合并,把多行数据合并成一行,比如把原来精确到秒的数据合并为分。ES中使用内嵌文档(Nested Document)实现公共字段的去从(比如应用名、ip、环境标识、metricsname)
如何加载更快?
如何利用索引和主存储,是一种两难的选择。
选择不使用索引,只使用主存储:除非查询的字段就是主存储的排序字段,否则就需要顺序扫描整个主存储。
这要求数据存储按照查询条件来选择主键(mysql中的聚簇索引),如果查询条件很多,会扫描整个文件。
选择使用索引,然后用找到的row id去主存储加载数据:这样会导致很多碎片化的随机读操作。
从硬盘上随机读写性能低
Lucene底层读取文件基于mmap,充分利用操作系统的特性来映射文件到内存(列式存储的优点是每列一个文件,可以充分利用mmap,加载需要的列),所以还是内存越大越好。
分布式聚合如何做得快?
通过数据分片,把数据分散到多台机器。在计算时,各个节点index计算聚合结果,然后汇总后在聚合。这样也减少了网络带宽,充分利用了各个节点的计算能力。
为什么时间序列需要更复杂的聚合?
通常会有降频(比如原来时间精确到秒,现在需要以分为单位)和降维(比如原来有地域纬度,统计时求所有地区)需求。ES支持Pipeline Aggregation可以实现数据在聚合之后再做聚合,能满足多次聚合的需求。
在mac osx中,docker deamon运行在virtualbox虚拟机中,docker client和虚拟机中的docker deamon交互。
#配置docker环境变量
eval "$(docker-machine env default)"
#配置docker启动alias
alias docker-start='docker-machine start default'
#配置docker关闭alias
alias docker-stop="docker-machine stop default"
启动命令如下:
docker-start
docker-stop
测试环境中私服提供服务如下:
#docker registry ui
http://192.168.46.21:10005/
#docker registry restful api
http://192.168.46.21:5000/v2/_catalog
下面配置docker registry私服为192.168.46.21:
#登陆到server
docker-machine ssh default
#修改/var/lib/boot2docker/profile
--insecure-registry 192.168.46.21:5000
--registry-mirror http://192.168.46.21:5000
国内docker mirror:
https://lug.ustc.edu.cn/wiki/mirrors/help/docker
http://0b929cdf.m.daocloud.io

#拉取镜像
docker pull yiji/java8:1.0
#查看镜像历史,能看到docker镜像层的细节
docker history yiji/java8:1.0
#删除镜像
docker rmi -f yiji/centos7:latest
#删除容器
docker rm
#执行命令
docker run yiji/centos7 /bin/echo 'hello world'
#交互运行:
docker run -it yiji/centos7 /bin/bash
#查看容器运行状态
docker ps -a
#查看指定容器状态
docker inspect f46935242662
#查看端口隐射,通过inspect结果过滤
docker inspect --format='{{.NetworkSettings.Ports}}' 8f4a179a0647
#查看容器资源占用
docker stats 92202cc1c3f0
#查看docker deamon运行ip
echo $DOCKER_HOST
#清理后台停止的容器
docker rm $( docker ps -a -q)
#查看镜像的环境变量
docker run yiji/java8:2.0 env
docker镜像的文件系统采用多层存储,镜像中全是只读层,便于分发和共享(pull镜像时,会在本地拉已经存在的层)。运行时建立读写层,对于应用来说,需要把文件系统mount到docker中(这样性能最好),device mapper对性能有影响。
Data volumes provide the best and most predictable performance. This is because they bypass the storage driver and do not incur any of the potential overheads introduced by thin provisioning and copy-on-write. For this reason, you may want to place heavy write workloads on data volumes.
制作基础镜像时权衡镜像大小(虽然可以在主机上缓存基础镜像,也需要考虑首次分发的大小)。我们最开始使用centos7来制作基础镜像,发现镜像300多M,如果在加上java8,基础镜像有600多M了。
可以参考frolvlad/alpine-oraclejdk8来制作基础镜像。
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
yiji/java8 2.0 1d58b31d19a0 4 days ago 166.5 MB
java8的基础镜像只有不到200m。
编写Dockerfile
FROM yiji/java8:2.0
COPY yiji-boot-test-1.1-SNAPSHOT.jar /opt/yiji-boot-test-1.1-SNAPSHOT.jar
WORKDIR /opt
ENTRYPOINT java -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=4004 -jar /opt/yiji-boot-test-1.1-SNAPSHOT.jar
build
docker build -t yiji-boot-test:1.0 .
run
docker run -p 8081:8081 -p 4004:4004 yiji-boot-test:1.0
其中8081是应用web端口,4004端口是远程调试端口
在容器内执行命令
在容器运行起来后,我们需要去容器内check下情况。
docker exec -it 92202cc1c3f0 sh
docker 容器运行的文件存储在本地。下面来看看这些文件:
查看docker container id
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
8f4a179a0647 yiji-boot-test:1.0 "/bin/sh -c 'java -ag" 2 hours ago Up 2 hours 0.0.0.0:4004->4004/tcp, 0.0.0.0:8081->8081/tcp silly_northcutt
登陆到虚拟机,在mac和windows下,docker在虚拟机中运行
docker-machine ssh default
切换到docker运行目录
sudo su -
cd /var/lib/docker/aufs/mnt/
ls |grep 8f4a179a0647发现两个目录
8f4a179a064737658b4055fb785c432c843f473a9d5fc40fba445017bd5b7e2e
8f4a179a064737658b4055fb785c432c843f473a9d5fc40fba445017bd5b7e2e-init
进入到第一个目录的opt子目录下,会找到我们打包的jar文件(chroot的魔力所在)
root@default:/mnt/sda1/var/lib/docker/aufs/mnt/8f4a179a064737658b4055fb785c432c843f473a9d5fc40fba445017bd5b7e2e/opt# ls -l
total 67168
-rw-r--r-- 1 root root 68777433 Dec 28 08:26 yiji-boot-test-1.1-SNAPSHOT.jar
我们需要做两件事情,
不要使用root in docker
经常升级内核
做安全的同学可以看看更多关于docker 安全的文章:
最后引用David Mortman在2015年Defcon的一句话:
a year ago, [docker and security] was pretty horrible,six months ago it wasn’t so bad, and now it’s pretty usable.
一些观点:
2016年六大OpenStack & Docker发展趋势预测
由原本的虚拟机管理程序为核心转变为容器加裸机组合模式
OpenStack是一个用于构建和管理云的IaaS框架,Hypernetes使用了它的部分组件。它使用OpenStack的身份和服务目录提供程序Keystone进行身份验证和授权。它还使用了其他的OpenStack组件,如用于存储的Cinder和Ceph,用于网络管理的Neutron。对于OpenStack而言,这是一个独特的用法,因为其组件通常都不在OpenStack部署之外使用。
查看docker信息:
curl --unix-socket /var/run/docker.sock http:/info |jq
api文档:
https://docs.docker.com/engine/reference/api/docker_remote_api/
依赖:
<dependency>
<groupId>com.github.docker-java</groupId>
<artifactId>docker-java</artifactId>
<version>3.0.1</version>
<exclusions>
<exclusion>
<groupId>de.gesellix</groupId>
<artifactId>unix-socket-factory</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.kohlschutter.junixsocket</groupId>
<artifactId>junixsocket-common</artifactId>
<version>2.0.4</version>
</dependency>
<dependency>
<groupId>com.kohlschutter.junixsocket</groupId>
<artifactId>junixsocket-native-common</artifactId>
<version>2.0.4</version>
</dependency>
使用:
DockerClient dockerClient = DockerClientBuilder.getInstance("unix:///var/run/docker.sock").build();
Info info = dockerClient.infoCmd().exec();
System.out.print(info);
api文档:
https://github.com/docker-java/docker-java/
centos7使用systemd来管理服务,docker配置文件/lib/systemd/system/docker.service。比如增加tcp api端口,修改
ExecStart=/usr/bin/dockerd
ExecStart=/usr/bin/dockerd -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock --insecure-registry catalog.shurenyun.com
昨天给朋友推荐了React,但心里还真没有底,这里整理下资料,如果不考虑浏览器兼容性的问题,这东东真不错😄。
虚拟DOM是HTML DOM的抽象,它和浏览器的实现分离。
DOM拖慢JavaScript。所有的DOM操作都是同步的,会堵塞浏览器。JavaScript操作DOM时,必须等前一个操作结束,才能执行后一个操作。只要一个操作有卡顿,整个网页就会短暂失去响应。浏览器重绘网页的频率是60FPS(即16毫秒/帧),JavaScript做不到在16毫秒内完成DOM操作,因此产生了跳帧。虚拟dom的改变并不会引起浏览器dom的改变,而是由React在合适的时机比较差异并渲染,保证FPS。
React knows when to re-render the scene because it is able to observe when this data changes. Dirty checking is slower than observables because you must poll the data at a regular interval and check all of the values in the data structure recursively. By comparison, setting a value on the state will signal to a listener that some state has changed, so React can simply listen for change events on the state and queue up re-rendering.(这点随着es6的Proxy到来,AngularJS会越来越强大😄)
Compared to dirty-check, the key differences IMO are:
Model dirty-checking: React component is explicitly set as dirty whenever setState is called, so there’s no comparison (of the data) needed here. For dirty-checking, the comparison (of the models) always happen each digest loop.
DOM updating: DOM operations are very expensive because modifying the DOM will also apply and calculate CSS styles, layouts. The saved time from unnecessary DOM modification can be longer than the time spent diffing the virtual DOM.
Template languages express the initial render of your application, and you’re responsible for manually mutating the state of the UI when your backing data changes and events occur.

上面部分是用户触发的,下面部分是定时触发的。
首先说上面部分:
top-level event handler分发事件到指定的event handler
top-level event handler指的是document上的event handler,这种方式能够提高性能(因为在每个真实的dom上面绑定事件是非常慢的)并且跨浏览器(浏览器中的事件本身就没有统一)
用户代码调用setState()
AngularJS双向绑定,不需要用户调用状态变更。所以,必须要去做大量的dirty check。虽然是一种倒退,但是为了性能忍了,等ES6吧。
下面部分的逻辑:event loop周期性的检查有状态组件是否dirty,然后通过diff算法批量更新浏览器dom树。